













































































































Google Perbaiki Celah Keamanan IDE Antigravity yang Memungkinkan Eksekusi Kode Melalui Prompt Injection

Google telah menambal kerentanan serius dalam lingkungan pengembangan terintegrasi (IDE) agentik mereka, Antigravity, yang memungkinkan penyerang melakukan eksekusi kode arbitrer melalui teknik prompt injection. Celah ini pertama kali diungkap pada 7 Januari 2026 dan diperbaiki resmi pada 28 Februari 2026.
Bagaimana Kerentanan Antigravity IDE Terjadi?
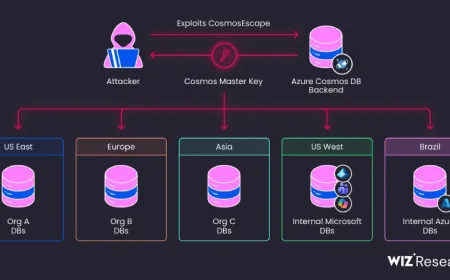
Kerentanan ini memanfaatkan kombinasi dua fitur Antigravity: kemampuan pembuatan file yang diizinkan dan kurangnya sanitasi input yang ketat pada alat pencari file bawaan bernama find_by_name. Dalam mode keamanan ketat (Strict Mode), Antigravity membatasi akses jaringan, mencegah penulisan di luar ruang kerja, dan menjalankan perintah di dalam sandbox. Namun, panggilan ke find_by_name dieksekusi sebelum pembatasan Strict Mode berlaku, sehingga input yang diterima tidak divalidasi dengan ketat dan langsung diteruskan ke perintah sistem fd.
"Dengan menyuntikkan flag -X (exec-batch) melalui parameter Pattern pada find_by_name, penyerang dapat memaksa fd menjalankan binary sembarangan terhadap file di workspace," ujar Dan Lisichkin dari Pillar Security.
Flag -X pada fd membuat setiap file yang cocok diproses sebagai skrip shell. Dengan menyisipkan pola seperti -Xsh, penyerang dapat menjalankan skrip berbahaya tersembunyi melalui perintah pencarian file yang terlihat sah. Kombinasi kemampuan Antigravity untuk membuat file dan eksekusi ini menciptakan rantai serangan lengkap tanpa interaksi pengguna tambahan setelah prompt injection berhasil.
Metode Serangan dan Dampaknya
Serangan ini bisa terjadi secara langsung melalui prompt injection dengan mengontrol parameter Pattern, atau secara tidak langsung tanpa perlu mengakses akun pengguna. Misalnya, pengguna bisa saja membuka file dari sumber tidak terpercaya yang berisi komentar tersembunyi yang menginstruksikan AI untuk menjalankan exploit.
- Memanfaatkan kelemahan sanitasi input pada find_by_name.
- Menyisipkan flag -Xsh untuk menjalankan skrip berbahaya.
- Membuat file berbahaya yang kemudian dijalankan secara otomatis.
- Bisa dilakukan tanpa perlu akses akun pengguna.
Kerentanan ini menunjukkan bahwa alat yang dirancang untuk operasi terbatas bisa menjadi vektor serangan jika inputnya tidak divalidasi dengan ketat. Menurut Lisichkin, asumsi bahwa manusia akan mengenali sesuatu yang mencurigakan tidak lagi relevan ketika agen otonom mengikuti instruksi dari konten eksternal.
Konteks Lebih Luas: Serangkaian Kerentanan AI yang Terungkap
Penemuan celah di Antigravity ini bertepatan dengan serangkaian kerentanan lain yang ditemukan dan telah diperbaiki pada berbagai alat AI dan pengembangan perangkat lunak, termasuk:
- Anthropic Claude Code, Google Gemini CLI, dan GitHub Copilot Agent, yang rentan terhadap prompt injection via komentar GitHub, memungkinkan pencurian token dan kunci API.
- Sebuah kerentanan serius bernama NomShub pada editor kode AI Cursor yang dapat memberikan akses shell persisten dan tersembunyi setelah membuka repositori berbahaya.
- Serangan ToolJack yang mengubah persepsi agen AI terhadap lingkungannya secara real-time, menghasilkan data dan rekomendasi palsu.
- Kerentanan pada Microsoft Copilot Studio dan Salesforce Agentforce yang memungkinkan pencurian data sensitif melalui form eksternal.
- Chain serangan Claudy Day pada Claude yang memungkinkan pembajakan sesi chat dan pencurian data hanya dengan satu klik melalui URL berbahaya yang disamarkan sebagai iklan Google.
Menurut penelitian terbaru, manipulasi metadata Git juga dapat menipu agen AI untuk menyetujui pull request berisi kode berbahaya, memperlihatkan risiko besar dari kepercayaan berlebihan pada sistem AI yang tidak deterministik.
Analisis Redaksi
Menurut pandangan redaksi, kerentanan pada Antigravity IDE ini menjadi peringatan penting bagi pengembang dan pengguna AI bahwa keamanan alat AI agentik harus menjadi prioritas utama. Ketergantungan pada input eksternal tanpa validasi ketat membuka peluang eksploitasi yang bisa berdampak luas, termasuk kebocoran data, eksekusi kode berbahaya, dan penyusupan sistem.
Lebih jauh, pola serangan yang ditemukan menunjukkan ancaman yang tidak hanya terbatas pada satu platform atau aplikasi, tapi bisa meluas ke berbagai sistem otomatisasi dan integrasi AI lainnya. Hal ini menggarisbawahi kebutuhan akan pengawasan keamanan yang berlapis, serta desain sistem yang tidak semata-mata mengandalkan kepercayaan pada input atau metadata yang tidak tervalidasi.
Ke depan, pembaruan rutin, audit keamanan intensif, dan pelatihan kesadaran keamanan bagi pengembang dan pengguna AI menjadi sangat penting. Pembaca disarankan untuk terus mengikuti perkembangan keamanan AI dan mengadopsi praktik terbaik dalam menggunakan teknologi AI secara aman.
Untuk informasi lebih lengkap, silakan kunjungi artikel asli di The Hacker News dan sumber terpercaya lainnya seperti Kompas Tekno.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0

















